JSON-Datenverarbeitung mit Zeus-Common-APIs

Image licensed by Ingram Image/adpic
Willkommen in der Welt der fortschrittlichen Datenverarbeitung! In diesem Beitrag tauchen wir in die spannende Welt der JSON-Datenverarbeitung ein. Wir beleuchten, wie JSON in verschiedenen Datenbanksystemen, insbesondere in NoSQL- und relationalen Datenbanken, effizient gespeichert und verwaltet werden kann.
Strategien zur Verarbeitung und Speicherung von JSON-Daten: Von NoSQL bis zu relationalen Datenbanken und dem Entity–attribute–value model
1. JSON in NoSQL-Datenbanksystemen: NoSQL-Datenbanken, bekannt für ihre Flexibilität und Skalierbarkeit, sind ideal für die Speicherung von JSON-Daten. Sie erlauben eine schemafreie Datenspeicherung, was bedeutet, dass sich die Datenstruktur dynamisch an die Anforderungen anpassen kann. Beispiele für solche Systeme sind MongoDB, Couchbase und Cassandra.
Während NoSQL-Systeme ihre eigenen Vorteile bieten, stellen relationale Datenbanksysteme eine andere Art der Herausforderung und Möglichkeit für die Verarbeitung von JSON dar.
2. JSON in relationalen Datenbanksystemen: Die Speicherung von JSON in relationalen Datenbanken wie MySQL, PostgreSQL oder Oracle stellt eine interessante Herausforderung dar. Hier kommen Techniken wie Objekt-Mapping und das Speichern von JSON in einem Datenbankfeld zum Einsatz. Einige relationale Datenbanksysteme bieten auch spezielle Erweiterungen für die JSON-Verarbeitung an.
3. Beispiel: JSON_TABLE in DB2/400: Die JSON_TABLE-Funktion in DB2/400 ist ein perfektes Beispiel dafür, wie relationale Datenbanksysteme JSON-Daten verarbeiten können. Diese Funktion ermöglicht es, JSON-Daten in eine virtuelle Tabelle umzuwandeln, sodass sie wie normale Tabellendaten abgefragt werden können.
4. Flexibilität des EAV-Modells: Das Entity-Attribute-Value (EAV)-Modell bietet eine flexible Alternative zur traditionellen tabellenbasierten Datenmodellierung. Es ermöglicht die Speicherung von Daten in einer dynamischen und erweiterbaren Form, ideal für heterogene oder sich schnell ändernde Datenstrukturen.
Zeus-Common-APIs und das Entity-Attribute-Value (EAV) Modell
Das Entity-Attribute-Value (EAV) Modell ist eine Datenmodellierungstechnik, die besonders nützlich ist, um hochvariante Datenstrukturen in relationalen Datenbanken darzustellen. Im EAV-Modell wird jede Entität (zum Beispiel ein Produkt oder ein Patient in einer medizinischen Datenbank) durch eine eindeutige ID repräsentiert. Jedes Attribut dieser Entität wird als separate Datensatzzeile gespeichert. Dieses Modell ermöglicht eine enorme Flexibilität, da es einfach ist, neue Attribute hinzuzufügen, ohne die gesamte Datenbankstruktur zu ändern.
Im Kontext der Zeus-Common-APIs wird das EAV-Modell auf eine innovative Weise implementiert. Die DynamicJsonObject-Klasse ermöglicht es, JSON-Daten dynamisch zu verarbeiten und zu speichern. Sie speichert Attribute und Metadaten in einer HashMap, was eine flexible Handhabung von Daten ermöglicht. Diese Attribute und Metadaten können dann in EAV-Tabellen in einer relationalen Datenbank abgebildet werden, wobei jedes Attribut und jedes Metadatum als separater Eintrag gespeichert wird.
Der JSONProcessor spielt dabei eine Schlüsselrolle, indem er JSON-Strings analysiert und in DynamicJsonObject-Instanzen umwandelt. Dieser Prozess beinhaltet die Zerlegung des JSON-Strings in einzelne Elemente, die entweder als Metadaten oder als weitere DynamicJsonObject-Instanzen verarbeitet werden. Diese Flexibilität ermöglicht es, komplexe und verschachtelte JSON-Strukturen effizient zu verarbeiten und in das EAV-Modell zu integrieren.
Die UniqueIdGenerator-Klasse ergänzt dieses System, indem sie eindeutige IDs für die DynamicJsonObject-Instanzen generiert. Diese IDs werden durch Hashing der Objektdaten zusammen mit einem Zeitstempel erzeugt, wodurch sichergestellt wird, dass jede ID einzigartig und konsistent ist.
Zusammenfassend bietet die Implementierung des EAV-Modells in den Zeus-Common-APIs eine leistungsstarke und flexible Lösung für die Speicherung und Verarbeitung von JSON-Daten in relationalen Datenbanken. Diese Herangehensweise maximiert die Vorteile des EAV-Modells, insbesondere seine Anpassungsfähigkeit und Erweiterbarkeit, was sie ideal für komplexe Datenstrukturen macht.
Der Aufruf des Clients erfolgt über folgenden Befehl:
java -cp zeus-commons-0.0.1-SNAPSHOT.jar de.zeus.commons.consumer.Consumer "JSON_EAV" "jdbc-properties-file" "json-client-config-file"
Der Aufruf des REST-Service erfolgt über folgenden Befehl:
java -cp zeus-commons-0.0.1-SNAPSHOT.jar de.zeus.commons.provider.Provider "REST" "jdbc-properties-file" "spark-properties-file"
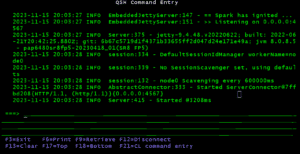
Provider-REST-Service
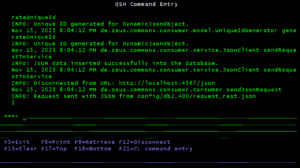
Consumer-REST-Client

 Image licensed by Ingram Image/adpic
Image licensed by Ingram Image/adpic Image licensed by Ingram Image/adpic
Image licensed by Ingram Image/adpic